RL for MEMS-based Reservoir Computer
(in progress)
Agent GIFs (the fun stuff)
CartPole-v1 - DQN
An inverted pendulum balancing game.
On the right are the internals of the reservoir which shows the MEMS response to different states of the game.
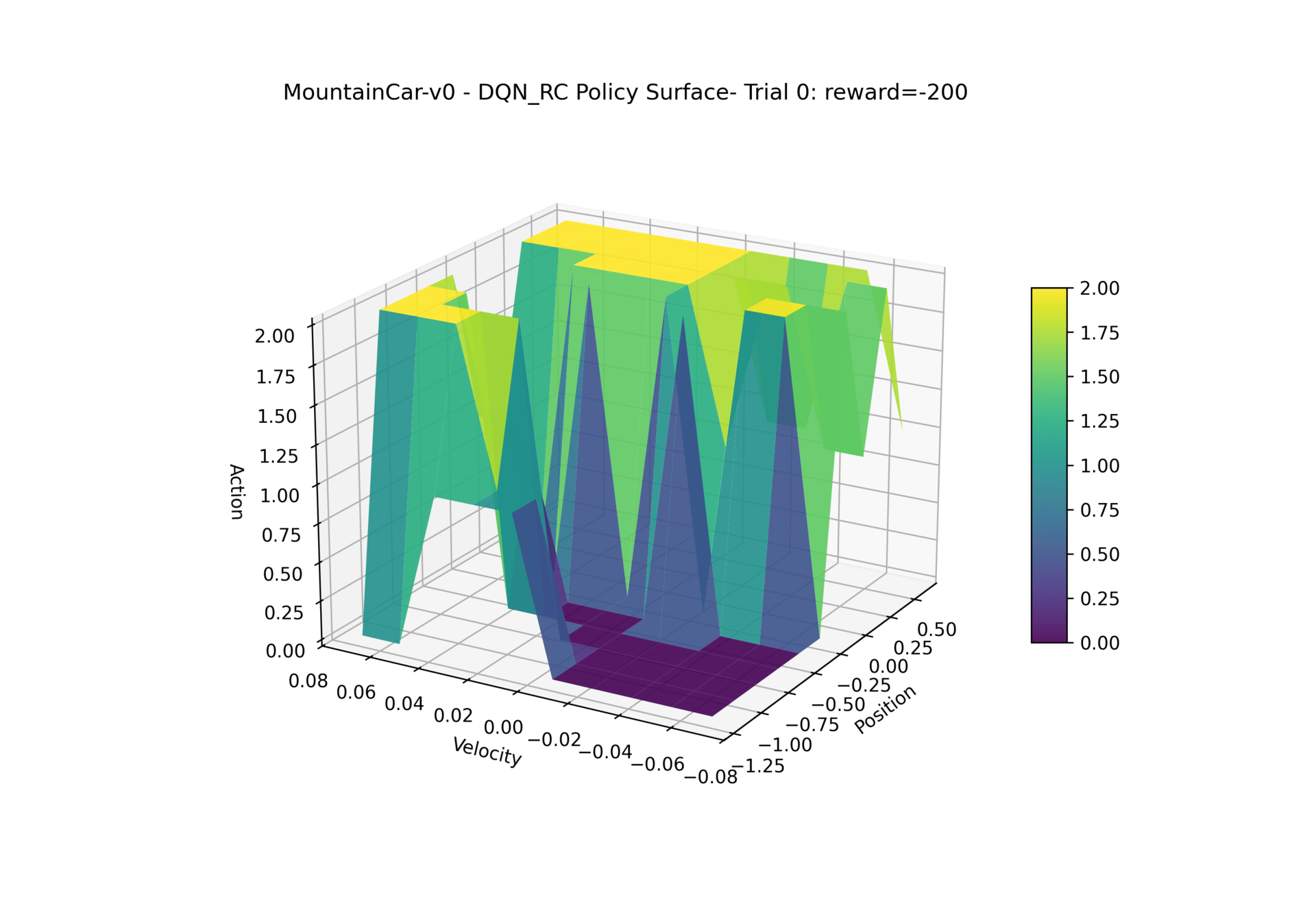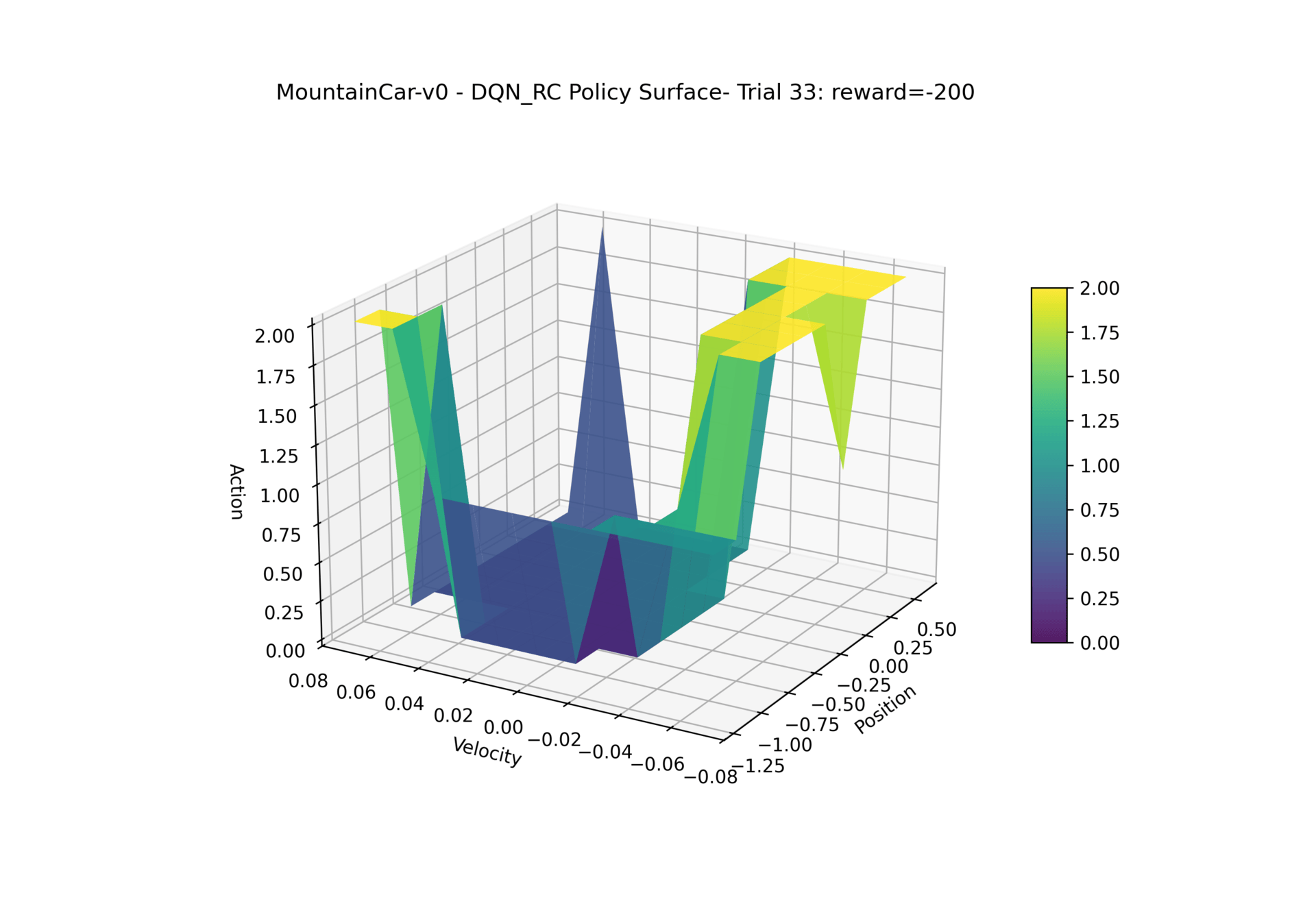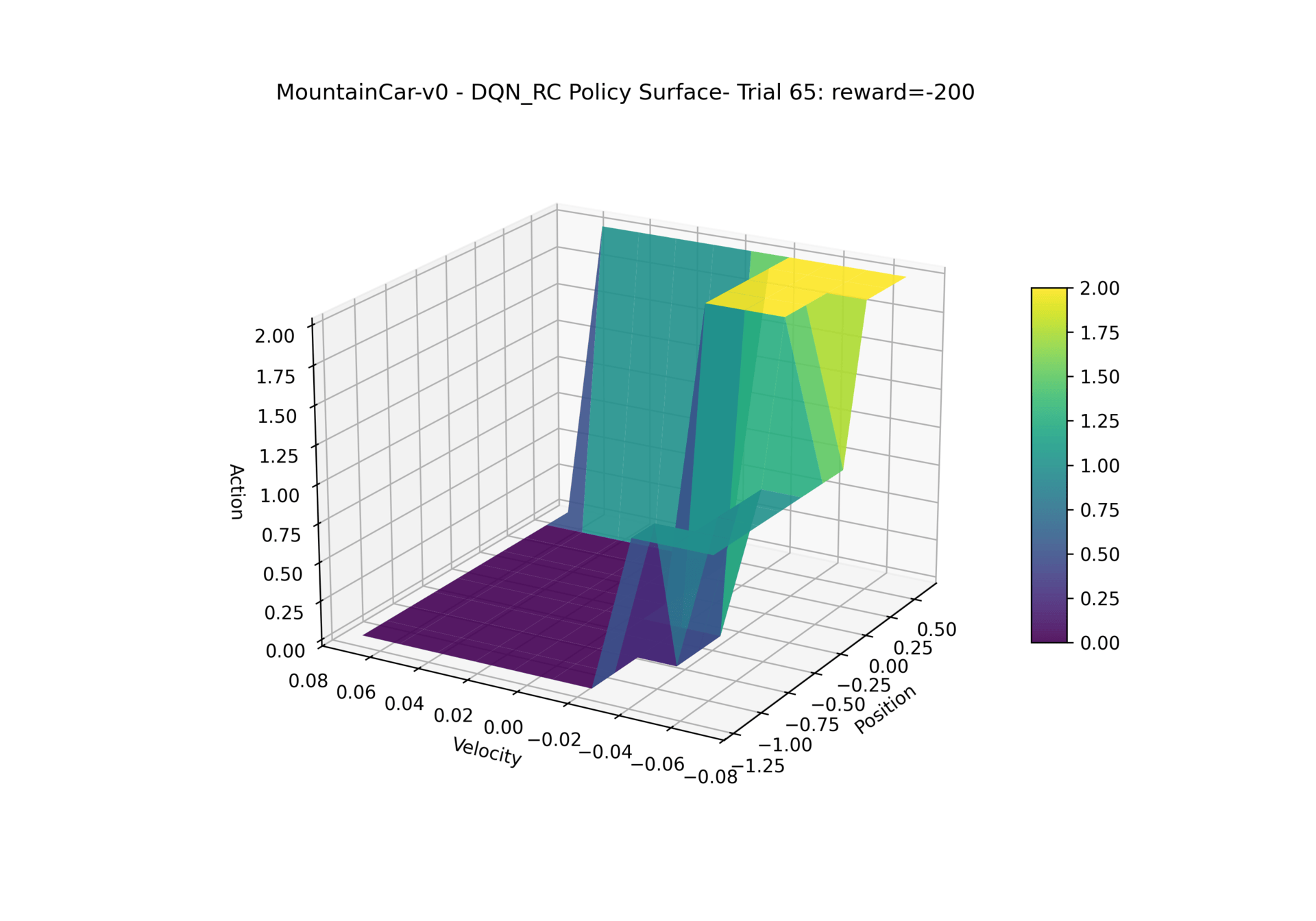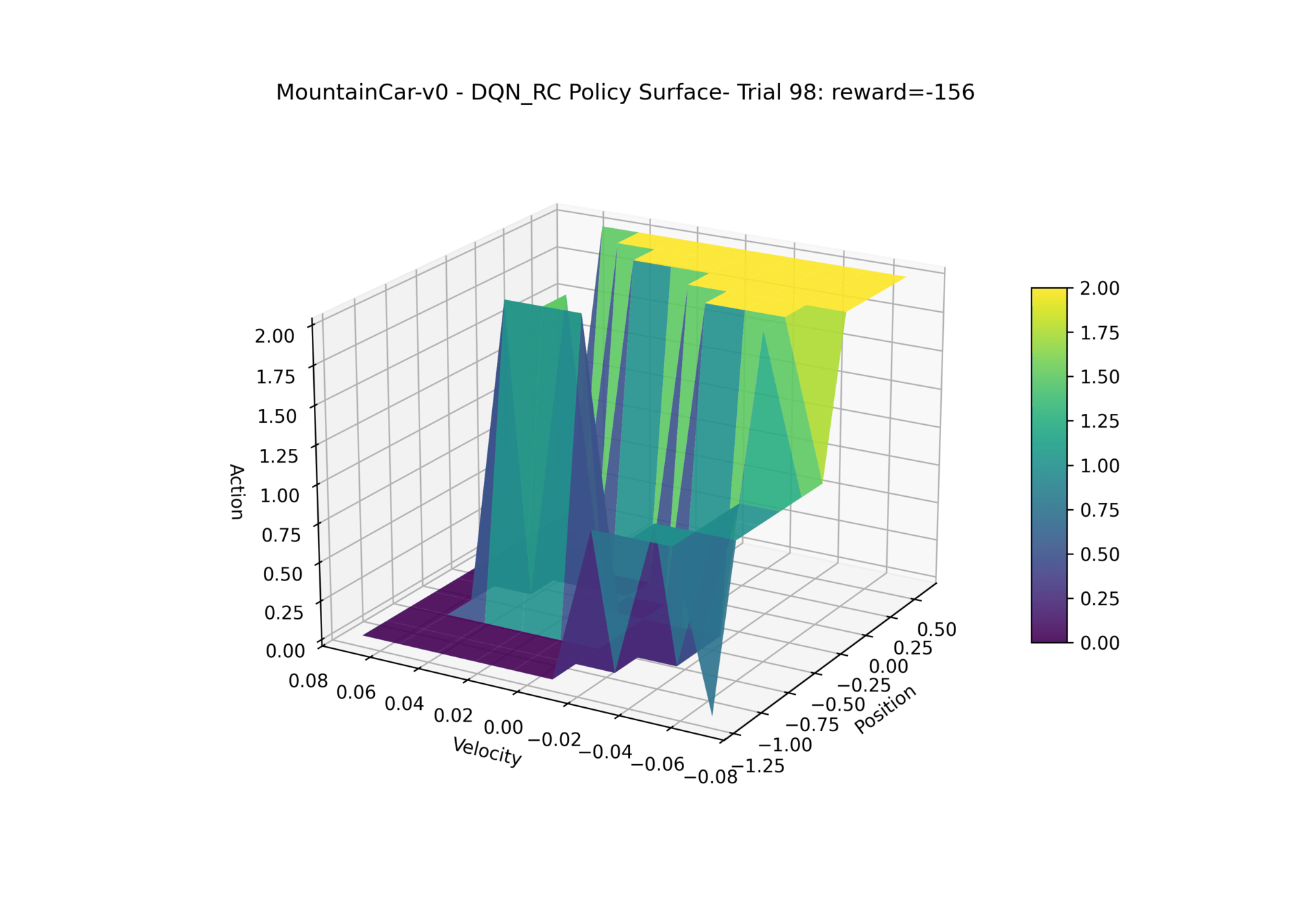
MountainCar-v0 - DQN
The agent needs to figure out how to escape the valley with discrete action choices of left, right or none.
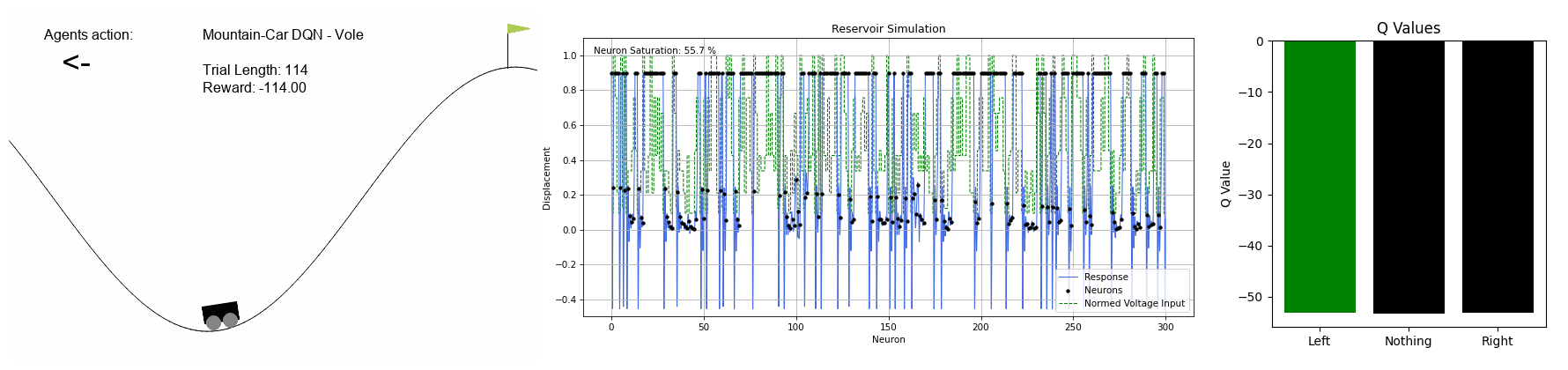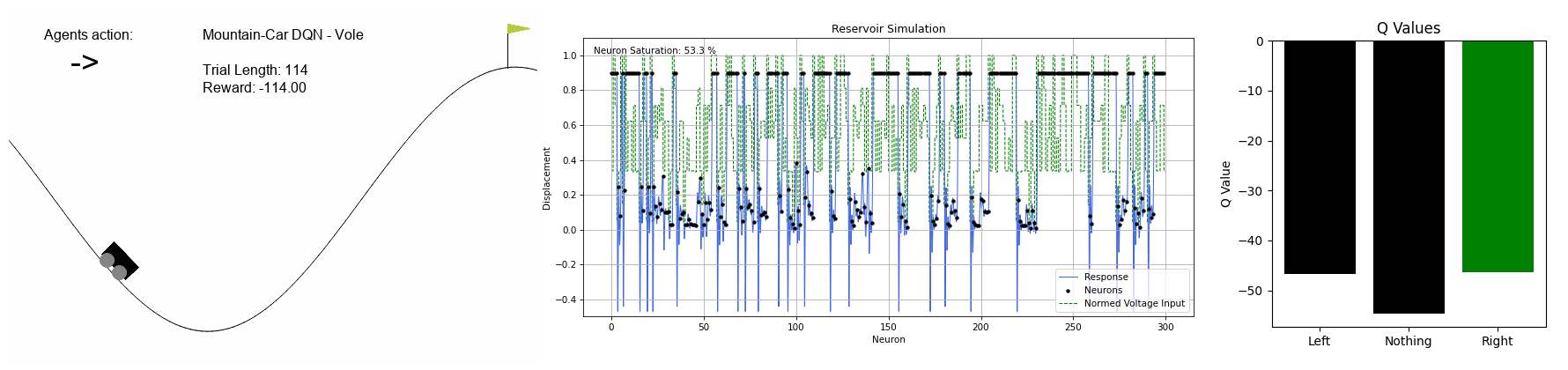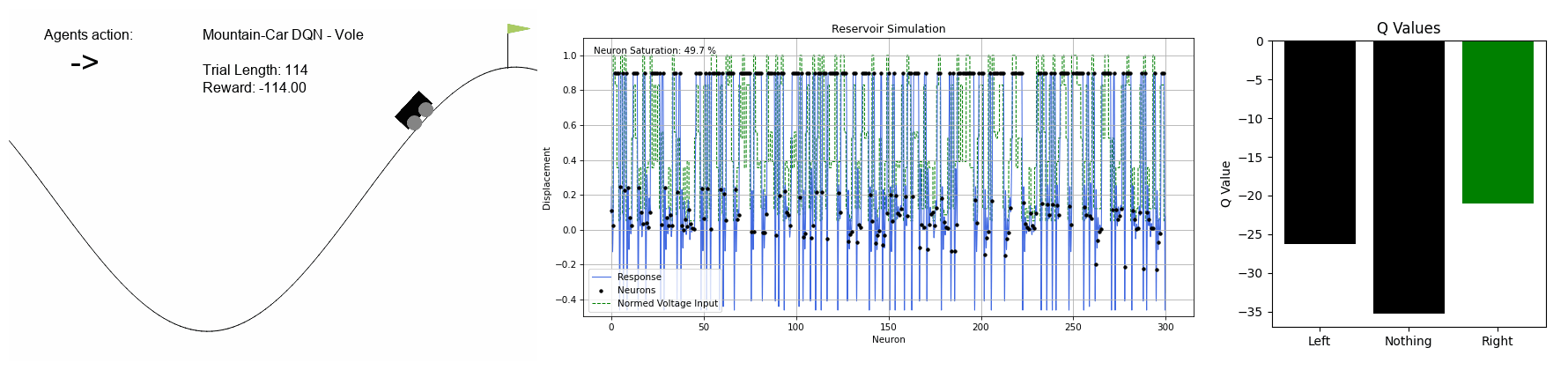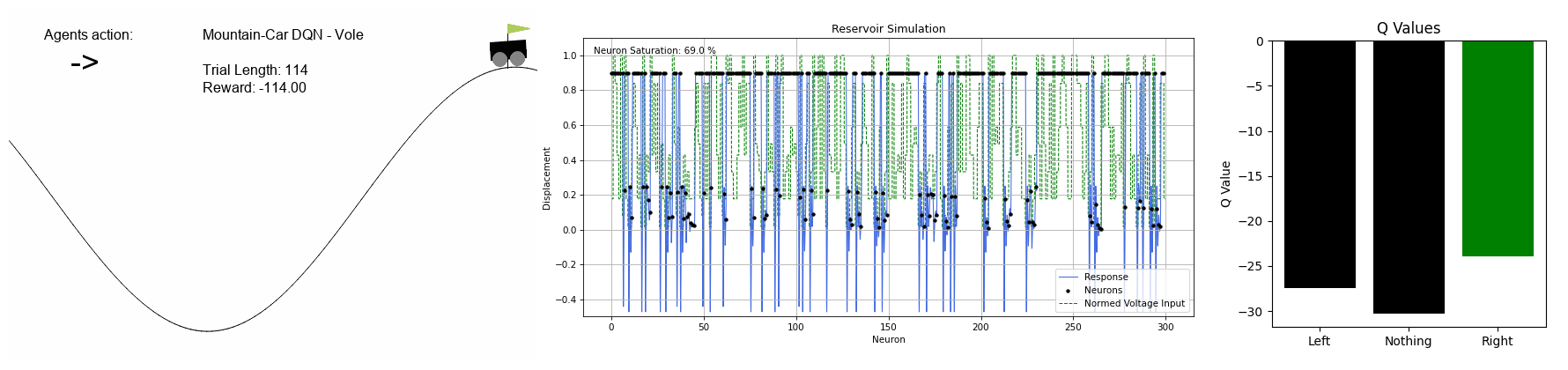
Reservoir internals are shown as well as the Q-values associated with each action for each state of the game.
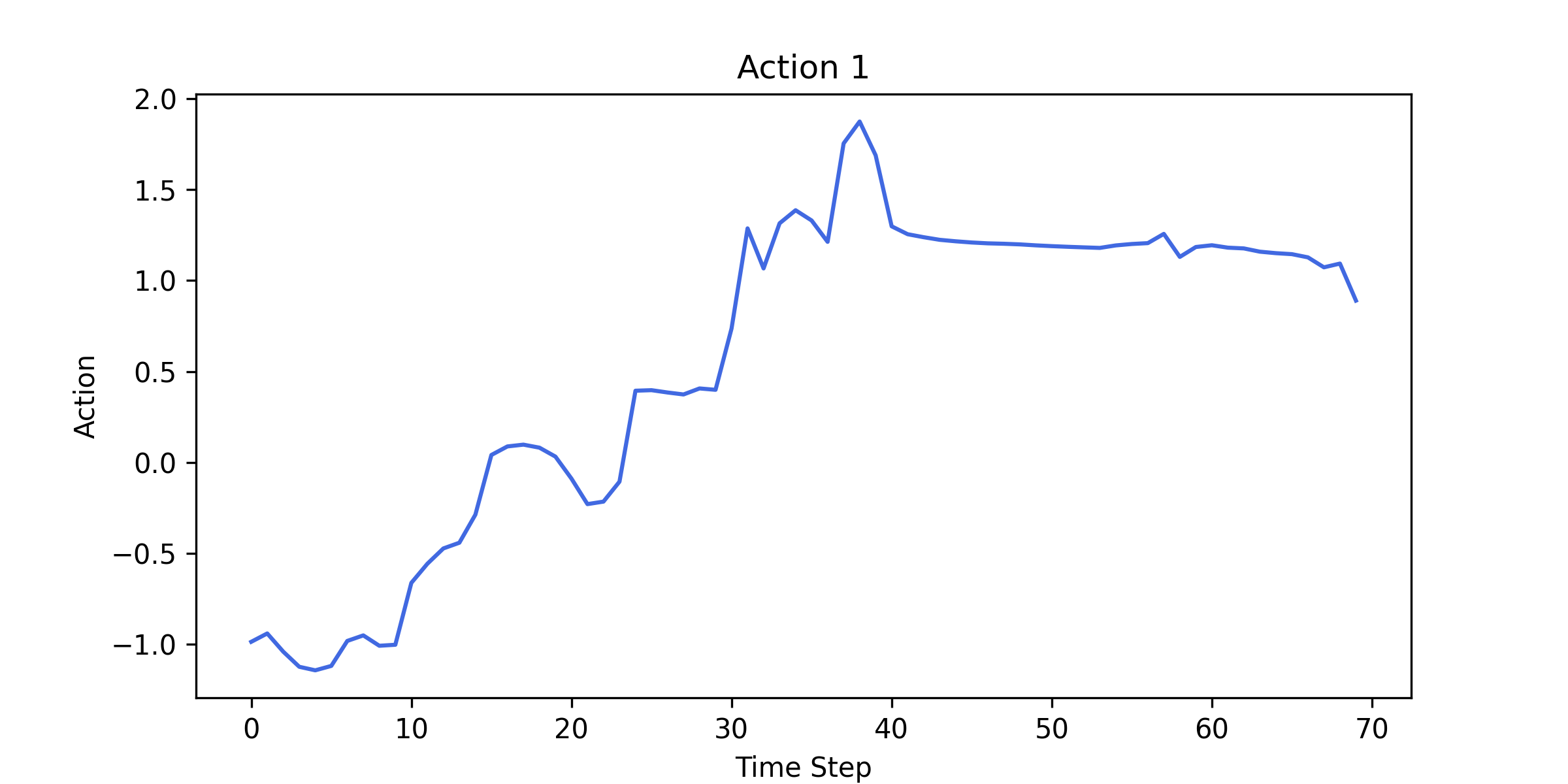
Here is how our DQN policy changes throughout training:
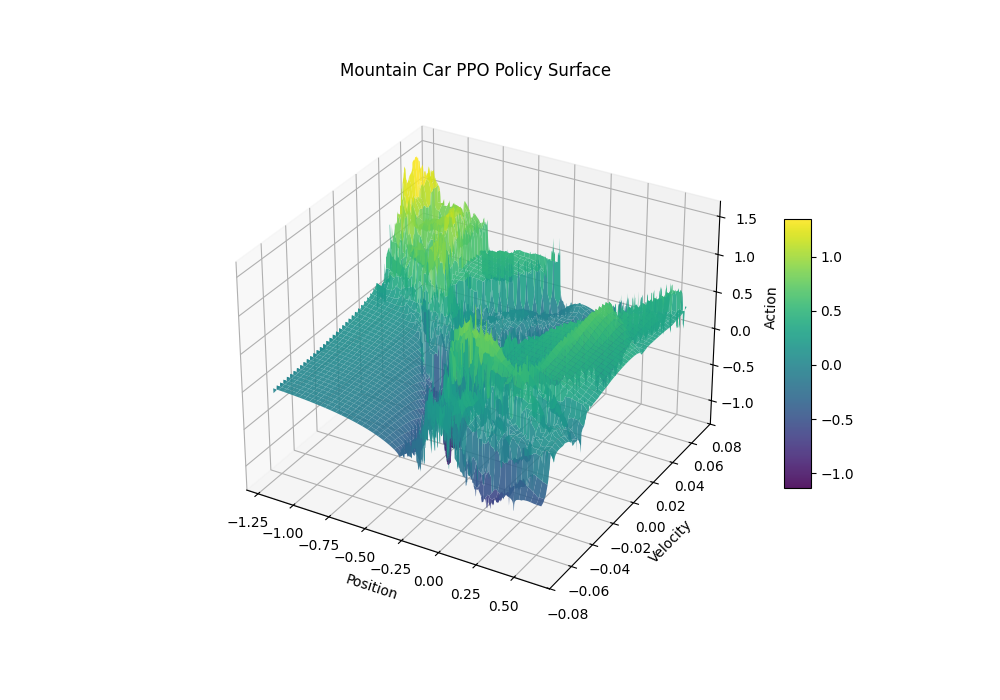
MountainCar-v0 - PPO
The agent needs to figure out how to escape the valley but with a continuous gas pedal.

PPO policy map for the above agent (what it chooses for each state observation):
LunarLander-v3 - DQN
The agent needs to slowly descend the spacecraft to the moon.
This is not a main focus of the project but the same hyperparameters from Mountain Car and Cart Pole work for it.
BipedalWalker-v3 - PPO
The agent needs learn how to walk, outputting motor torques directly.

This is the final task of the project, meant to show the limits and potential of learning on the MEMS-RC.
The Project
My master’s thesis at Cal Poly is the implementation of reinforcement learning algorithms on a simulated MEMS-based reservoir computer.
On the reinforcement side, my work focuses on implementing RC-specific versions of two algorithms: DeepMind’s DQN, a value-based approach, and OpenAI’s PPO, a policy gradient approach. Due to the linear readout layer, these algorithms follow the ANN approach closely; however, RC PPO requires less coupling of the actor and critic objective functions, hopefully leading to more efficient training. The successful implementation of each of these algorithms proves the compatibility of RL algorithms with MEMS RC hardware.
On the RC side, I am investigating the effects of RC hyperparameters on a model’s learning performance. Utilizing tools like Ray Tune, I am running investigative grid searches, comparing the effects of each hyperparameter. I look at the learning performance of two main parameters, neuron count N and neuron separation 𝜃.
Articles
We have recently submitted to the ACM ICONS 2026 conference. Here is the abstract for our paper:
Reservoir computing (RC) offers a promising approach for lowpower, low-latency machine learning by leveraging the intrinsic dynamics of physical systems. In this work, we investigate a microelectromechanical system (MEMS)-based delay reservoir computer as a function approximator for reinforcement learning (RL). Specifically, a single MEMS oscillator is used to implement a virtual reservoir within a Deep Q-Network (DQN) framework and evaluated on two benchmark control tasks: CartPole-v1 and MountainCar-v0. We perform a comprehensive parametric study to analyze the impact of key reservoir hyperparameters, including the number of virtual nodes, node separation, and delayed feedback. The node separation𝜃 , which determines the temporal spacing of virtual neurons relative to the MEMS natural frequency, is shown to critically influence system dynamics and learning performance. Results demonstrate that for CartPole-v1, optimal and consistent performance occurs for relatively small 𝜃 , corresponding to input frequencies higher than the MEMS natural frequency. In contrast, MountainCar-v0 benefits from moderate 𝜃 , where the reservoir operates closer to its natural timescale and exhibits stronger nonlinear dynamics. Furthermore, the inclusion of delayed feedback significantly enhances performance in more complex tasks by increasing dynamical richness and shifting the optimal operating regime. Across both tasks, increasing reservoir size improves performance and robustness. These results highlight the importance of matching reservoir temporal dynamics to task requirements and demonstrate that MEMS-based reservoirs can serve as compact, energy-efficient computing cores for reinforcement learning in edge robotic systems.
Some Background
This is a short introduction into what the main topics of my thesis are: reservoir computing (specifically on a MEMS device) and reinforcement learning.
Reservoir Computing
Reservoir computing (RC), a subset of the neuromorphic genre, uses a highly dynamic system to represent a sparsely connected neural net. One choice of a ‘reservoir’ is a Micro-Electro-Mechanical System (MEMS) device. By inputting a specific voltage signal, measuring the MEMS state at specific time points, and then feeding the outputs into a linear readout layer, we are left with a form of a recurrent neural network.
A major part of the system is the masking function. This encodes the inputs or states of our task in out voltage signal. As of now, the masking function is a random telegraph signal, either -1 to 1. There is a unique masking function to encode each input from our system. After our inputs are applied to their masking functions, we superimpose these signals and input the resultant to our MEMS system. The period of our masking function is called theta, which is normalized to be nondimensional. At each theta, we read the state of our MEMS state to get a ‘neuron’ reading. We have N neurons in our reservoir meaning that our masking signal is N*theta long. Each neuron has a equivelant weight and bias before as part of the readout layer. After the readout is applied to our neuron outputs, we have our reservoir computer output.
For example, lets use the classic cart pole game, an inverted pendulum on a cart balancing task where we know the position and velocity of the cart and the angular position and velocity of the pendulum. The two possible actions are to push the cart left or right. For our RC system, we take the 4 state observations, apply each of their masking functions, and input them into our MEMS system. We take our neuron readings, scale them with the readout layer, and use the output as our control signal.